
课程简介:
未来是什么时代?是数据时代!数据分析服务、互联网金融,数据建模、自然语言处理、医疗病例分析……越来越多的工作会基于数据来做,而爬虫正是快速获取数据最重要的方式,相比其它语言,Python爬虫更简单、高效。

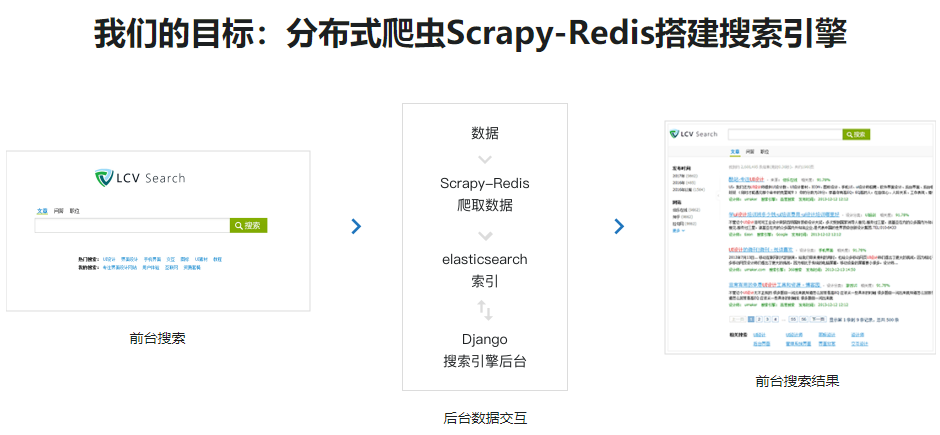
课程目录:
{1}–第1章课程介绍
[1.1]–1-1python分布式爬虫打造搜索引擎简介.mp4 40.60M
{2}–第2章windows下搭建开发环境
[2.1]–2-1pycharm的安装和简单使用.mp4 73.49M
[2.2]–2-2mysql和navicat的安装和使用.mp4 71.47M
[2.3]–2-3windows和linux下安装python2和pytho.mp4 41.24M
[2.4]–2-4虚拟环境的安装和配置.mp4 159.35M
[2.4]–2-4虚拟环境的安装和配置.mp4 180.66M
{3}–第3章爬虫基础知识回顾
[3.1]–3-1技术选型爬虫能做什么.mp4 33.76M
[3.2]–3-2正则表达式-1.mp4 115.90M
[3.3]–3-3正则表达式-2.mp4 114.94M
[3.4]–3-4正则表达式-3.mp4 123.28M
[3.5]–3-5深度优先和广度优先原理.mp4 120.62M
[3.6]–3-6url去重方法.mp4 47.84M
[3.7]–3-7彻底搞清楚unicode和utf8编码.mp4 152.43M
{4}–第4章新:scrapy爬取知名技术文章网站
[4.1]–4-1重录说明(很重要!!!).mp4 20.37M
[4.2]–4-2scrapy安装和配置.mp4 179.33M
[4.3]–4-3需求分析.mp4 95.98M
[4.4]–4-4pycharm中调试scrapy源码.mp4 63.51M
[4.5]–4-5xpath基础语法.mp4 115.90M
[4.6]–4-6xpath提取元素.mp4 170.34M
[4.7]–4-7css选择器.mp4 106.19M
[4.8]–4-8.cnblogs模拟登录(新增内容).mp4 145.35M
[4.9]–4-9编写spider完成抓取过程-1.mp4 113.66M
[4.10]–4-10编写spider完成抓取过程-2.mp4 126.45M
[4.11]–4-11scrapy中为什么要使用yield.mp4 61.67M
[4.12]–4-12提取详情页信息.mp4 137.24M
[4.13]–4-13提取详情页信息.mp4 108.89M
[4.14]–4-14items的定义和使用-1.mp4 98.86M
[4.15]–4-15items的定义和使用-2.mp4 78.53M
[4.16]–4-16scrapy配置图片下载.mp4 110.74M
[4.17]–4-17items数据写入到json文件中.mp4 58.98M
[4.18]–4-18mysql表结构设计.mp4 62.35M
[4.19]–4-19pipeline数据库保存.mp4 120.38M
[4.20]–4-20异步方式入库mysql.mp4 76.86M
[4.21]–4-21数据插入主键冲突的解决方法.mp4 28.45M
[4.22]–4-22itemloader提取信息.mp4 126.49M
[4.23]–4-23itemloader提取信息.mp4 118.38M
[4.24]–4-24大规模抓取图片下载出错的问题.mp4 79.13M
{5}–第5章网站模拟登陆和滑动验证码识别(2021.6月更新)
[5.1]–5-1session和cookie自动登录机制.mp4 111.13M
[5.2]–5-2课程如何应对网站反爬变化?.mp4 41.39M
[5.3]–5-3使用opencv识别滑动验证码的环境准备.mp4 99.12M
[5.4]–5-4opencv滑动验证码识别原理.mp4 157.95M
[5.6]–5-6通过机器学习平台训练滑动验证码模型.mp4 89.11M
[5.7]–5-7发布训练模型并远程调用识别.mp4 166.40M
{6}–第6章scrapy爬取知名问答网站
[6.1]–6-1知乎分析以及数据表设计1.mp4 93.98M
[6.2]–6-2知乎分析以及数据表设计-2.mp4 67.53M
[6.3]–6-3itemloder方式提取question-1.mp4 88.77M
[6.4]–6-4itemloder方式提取question-2.mp4 93.04M
[6.5]–6-5itemloder方式提取question-3.mp4 40.91M
[6.6]–6-6知乎spider爬虫逻辑的实现以及answer的提取-1.mp4 94.41M
[6.7]–6-7知乎spider爬虫逻辑的实现以及answer的提取-2.mp4 103.29M
[6.8]–6-8保存数据到mysql中-1.mp4 102.27M
[6.10]–6-10保存数据到mysql中-3.mp4 95.87M
{7}–第7章通过CrawlSpider对招聘网站进行整站爬取
[7.1]–7-1数据表结构设计.mp4 67.93M
[7.2]–7-2CrawlSpider源码分析-新建CrawlSpider.mp4 76.96M
[7.3]–7-3CrawlSpider源码分析.mp4 153.61M
[7.4]–7-4Rule和LinkExtractor使用.mp4 88.06M
[7.5]–7-5网页302之后的模拟登录和cookie传递(网站需要登录时.mp4 196.38M
[7.6]–7-6itemloader方式解析职位.mp4 148.05M
[7.7]–7-7职位数据入库-1.mp4 108.87M
[7.8]–7-8职位信息入库-2.mp4 68.99M
[7.9]–7-9网站反爬突破.mp4 68.01M
{8}–第8章Scrapy突破反爬虫的限制
[8.1]–8-1爬虫和反爬的对抗过程以及策略.mp4 149.65M
[8.2]–8-2scrapy架构源码分析.mp4 112.63M
[8.3]–8-3Requests和Response介绍.mp4 57.61M
[8.4]–8-4通过downloadmiddleware随机更换user-.mp4 101.05M
[8.5]–8-5通过downloadmiddleware随机更换user-.mp4 100.06M
[8.6]–8-6scrapy实现ip代理池-1.mp4 104.13M
[8.7]–8-7scrapy实现ip代理池-2.mp4 101.35M
[8.8]–8-8scrapy实现ip代理池-3.mp4 109.85M
[8.9]–8-9云打码实现验证码识别.mp4 141.23M
[8.10]–8-10cookie禁用、自动限速、自定义spider的sett.mp4 45.34M
{9}–第9章scrapy进阶开发
[9.1]–9-1selenium动态网页请求与模拟登录知乎.mp4 129.11M
[9.2]–9-2selenium模拟登录微博,模拟鼠标下拉.mp4 64.79M
[9.3]–9-3chromedriver不加载图片、phantomjs获取.mp4 60.32M
[9.4]–9-4selenium集成到scrapy中.mp4 115.71M
[9.5]–9-5其余动态网页获取技术介绍-chrome无界面运行、scra.mp4 48.40M
[9.6]–9-6scrapy的暂停与重启.mp4 89.51M
[9.7]–9-7scrapyurl去重原理.mp4 35.24M
[9.8]–9-8scrapytelnet服务.mp4 46.17M
[9.9]–9-9spidermiddleware详解.mp4 93.99M
[9.10]–9-10scrapy的数据收集.mp4 84.59M
[9.11]–9-11scrapy信号详解.mp4 81.85M
[9.12]–9-12scrapy扩展开发.mp4 80.75M
{10}–第10章scrapy-redis分布式爬虫
[10.1]–10-1分布式爬虫要点.mp4 26.52M
[10.2]–10-2redis基础知识-1.mp4 120.98M
[10.3]–10-3redis基础知识-2.mp4 105.81M
[10.4]–10-4scrapy-redis编写分布式爬虫代码.mp4 128.29M
[10.5]–10-5scrapy源码解析-connection.py、def.mp4 75.07M
[10.6]–10-6scrapy-redis源码剖析-dupefilter..mp4 31.60M
[10.7]–10-7scrapy-redis源码剖析-pipelines.p.mp4 65.82M
[10.8]–10-8scrapy-redis源码分析-scheduler.p.mp4 71.52M
[10.9]–10-9集成bloomfilter到scrapy-redis中.mp4 119.08M
{11}–第11章cookie池系统设计和实现
[11.1]–11-1什么是cookie池?.mp4 29.17M
[11.2]–11-2cookie池系统设计.mp4 25.68M
[11.3]–11-3实现cookie池-1.mp4 65.34M
[11.4]–11-4实现cookie池-2.mp4 73.44M
[11.5]–11-5改造login方法-1.mp4 62.32M
[11.6]–11-6改造login方法-2.mp4 53.80M
[11.7]–11-7改造login方法-3.mp4 54.39M
[11.8]–11-8改造login方法-4.mp4 62.62M
[11.9]–11-9通过抽象基类实现网站轻松接入.mp4 93.10M
[11.10]–11-10实现检测网站cookie是否有效.mp4 48.35M
[11.11]–11-11如何选择redis的数据结构来保存cookie.mp4 70.33M
[11.12]–11-12cookie管理器的实现.mp4 137.74M
[11.13]–11-13启动cookie池服务.mp4 75.53M
[11.14]–11-14将cookie集成到爬虫项目中.mp4 94.79M
[11.15]–11-15cookie架构设计改进意见.mp4 49.12M
{12}–第12章各种验证码的识别
[12.1]–12-1滑动验证码的识别思路.mp4 97.57M
[12.2]–12-2验证码截屏-1.mp4 68.91M
[12.3]–12-3验证码截屏-2.mp4 82.85M
[12.4]–12-4计算出滑动的距离.mp4 99.98M
[12.5]–12-5计算滑动轨迹.mp4 105.66M
{13}–第13章增量抓取
[13.1]–13-1增量爬虫需要解决的问题.mp4 59.98M
[13.2]–13-2通过修改scrapy-redis完成增量抓取-1.mp4 99.61M
[13.3]–13-3通过修改scrapy-redis完成增量抓取-2.mp4 86.85M
[13.4]–13-4爬虫数据更新.mp4 56.92M
{14}–第14章elasticsearch搜索引擎的使用
[14.1]–14-1elasticsearch介绍.mp4 110.80M
[14.2]–14-2elasticsearch安装.mp4 83.27M
[14.3]–14-3elasticsearch-head插件以及kibana.mp4 140.04M
[14.4]–14-4elasticsearch的基本概念.mp4 43.97M
[14.5]–14-5倒排索引.mp4 40.79M
[14.6]–14-6elasticsearch基本的索引和文档CRUD操作.mp4 114.20M
[14.7]–14-7elasticsearch的mget和bulk批量操作.mp4 85.93M
[14.8]–14-8elasticsearch的mapping映射管理.mp4 173.02M
[14.9]–14-9elasticsearch的简单查询-1.mp4 94.44M
[14.10]–14-10elasticsearch的简单查询-2.mp4 68.41M
[14.11]–14-11elasticsearch的bool组合查询.mp4 141.36M
[14.12]–14-12scrapy写入数据到elasticsearch中-1.mp4 89.49M
[14.13]–14-13scrapy写入数据到elasticsearch中-2.mp4 65.60M
{15}–第15章django搭建搜索网站
[15.1]–15-1es完成搜索建议-搜索建议字段保存-1.mp4 82.95M
[15.2]–15-2es完成搜索建议-搜索建议字段保存-2.mp4 85.07M
[15.3]–15-3django实现elasticsearch的搜索建议-1.mp4 118.27M
[15.4]–15-4django实现elasticsearch的搜索建议-2.mp4 113.09M
[15.5]–15-5django实现elasticsearch的搜索功能-1.mp4 83.42M
[15.6]–15-6django实现elasticsearch的搜索功能-2.mp4 80.17M
[15.7]–15-7django实现搜索结果分页.mp4 56.00M
[15.9]–15-9搜索记录、热门搜索功能实现-2.mp4 82.86M
{16}–第16章scrapyd部署scrapy爬虫
[16.1]–16-1scrapyd部署scrapy项目.mp4 156.36M
{17}–第17章课程总结
[17.1]–17-1课程总结.mp4 12.12M
课件
coding-92-master.zip 62.66M
本站资料仅供个人学习和研究使用 若本帖作者内容侵犯了原著者的合法权益请提供相应证明材料本站审核通过后将即予以处理






评论0